N + 1 Devices
cuDF-Polars can scale a familiar Polars query across multiple GPUs with only a few configuration changes
With cuDF-Polars 26.06, we have a new execution backend: RapidsMPF. RapidsMPF handles both execution and the distributed collectives needed for multi-GPU, out-of-core algorithms. That's a lot of verbiage. More simply, RapidsMPF gives cuDF-Polars a way to coordinate work and move data across workers/devices/ranks/etc.
In this post I want to start exploring the multi-GPU capabilities of cuDF-Polars.
When searching for more performance, more memory, more of anything, we often go to plaid -- wait, not plaid -- distributed. Well, sometimes distributed -- multiple GPUs, or multiple CPUs, or nodes, or clusters...but what we are really trying to get at is parallelism (not concurrency): how to run mulitple tasks at the same time.
Learning to use multiple devices may seem intimidating. N+1 of anything is often perceived as an advanced feature, or at least an intermediate one. But our hardware and software keep changing and we can find examples (perhaps even models) of excellence which offer parallelism wiht little to no visibility to the enduser. NumPy is one such example where multi-threaded execution is now avaiable without any effort or input from user. That's probably the decades of labor in underlying libraries like LAPACK/BLAS, a bunch of magic linking and packaging, and perhaps most importantly, thoughtful API design.
The GPU analytics world is still a somewhat nascent adventure, and we collectively are exploring how to deliver speed-of-light performance and ease of use without requiring extreme levels of expertise. For these reasons, the multi-GPU experience is typically opt-in and the user should be more cognizant of what they are opting into. Still, many libraries (PyTorch, XGBoost, HugginFace) including cuDF-Polars are actively exploring *and shipping• solutions which enable multi-GPU capabilities without requiring in-depth knowledge of GPU hardware or software.
With that said, if you find yourself on a single-node multi-GPU (SNMG) machine, you CAN leverage all this hardware with just a few additional engine configurations to otherwise standard Polars code. Recall that the out-of-box experience for most cuDF-Polars users is a single parameter change: collect(engine='gpu'). Now we just need to take the advanced step and define a multi-GPU engine explicitly:
from cudf_polars.engine.ray import RayEngine
engine = RayEngine()
result = (
pl.scan_parquet("/data/*.parquet")
.filter(pl.col("amount") > 100)
.group_by("customer_id")
.agg(pl.col("amount").sum())
.collect(engine=engine)
)
Hmmm, actually, not too bad. In fact, it's quite simple! The above will automatically start using all the GPUs in the same box. It even comes in ContextManager form for easy cleanup:
from cudf_polars.engine.ray import RayEngine
with RayEngine() as engine:
result = (
pl.scan_parquet("/data/*.parquet")
.filter(pl.col("amount") > 100)
.group_by("customer_id")
.agg(pl.col("amount").sum())
.collect(engine=engine)
)
This will automatically start one ray worker per GPU, and cuDF-Polars (RapidsMPF) will execute all the work evenly across each device. There is no scheduler here, for those familiar with task-based systems like Spark. Instead, all workers will get the same execution graph (a physical plan) and operate independently. Synchronization points are inserted into the physical plan where communication is required: groupby-aggregations, join/merges, etc. These higher level operations are composed of RapidsMPF atomic collectives common in distributed computing: shuffle (all-to-all), allgather, allreduce, sparse-all-to-all, etc. For now, let's stay above these details and continue exploring what kind of options are available to us.
I was able to get some time on a machine with 4 T4s. These are older and a bit smaller compared to more contemporary devices -- only 16GBs of VRAM/GPU -- but with four we have a whopping 64GBs!
$ nvidia-smi
Tue Jun 16 16:59:53 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.159.04 Driver Version: 580.159.04 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 Off | 00000000:60:00.0 Off | 0 |
| N/A 26C P8 12W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 Tesla T4 Off | 00000000:61:00.0 Off | 0 |
| N/A 35C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 2 Tesla T4 Off | 00000000:DA:00.0 Off | 0 |
| N/A 40C P8 13W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 3 Tesla T4 Off | 00000000:DB:00.0 Off | 0 |
| N/A 32C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
Make sure you install cuDF-Polars with Ray:
Speed Demons of the High Seas
We are going to play with vessel traffic data collected and maintained by the U.S. Coast Guard: Automatic Identification System (AIS) Vessel Data. It has a nice mix of traits for analytics: geospatial data, time-series, scale, skew, and some oddities to make the results fun without requiring deep maritime knowledge.
I downloaded all of 2025 and converted from CSV to Parquet with snappy compression. The first quarter (Jan-Feb) is ~19GBs on disk and uncompressed it's ~78GBs. I'll limit myself to the first quarter to keep the overall execution time to less than a minute. But we'll still need multiple GPUs, we'll need spilling, etc.
A more interesting analysis than simple scan-and-filter exploration is cohort analysis. Vessels are organized by group and type: Sailing, Fishing, Cargo, Passenger, Tug, and so on. The data also contains a velocity-like measurement, Speed over Ground (SOG). Let's find vessels whose speed is more than 10x their cohort average.
We could write this as an explicit group_by, join the cohort average back to the original table, and then filter:
cohort_avg = (
df
.group_by("VesselType", "Status")
.agg(pl.col("SOG").mean().alias("cohort_avg_speed"))
)
return (
df
.join(cohort_avg, on=["VesselType", "Status"], how="left")
.filter(pl.col("SOG") > (pl.col("cohort_avg_speed") * 10))
)
This is costly because it introduces two global synchronization points: group_by and join. Instead, we can remove the explicit join and use Polars’ over expression to compute the cohort average in place.
def build_speed_anomaly_query(path: str = DATA_GLOB) -> pl.LazyFrame:
"""Flag vessels travelling 10x faster than their cohort average (VesselType + Status).
"""
return (
pl.scan_parquet(path)
.filter(pl.col("VesselType").is_not_null() & pl.col("Status").is_not_null())
.with_columns(
pl.col("SOG")
.mean()
.over(["VesselType", "Status"])
.alias("cohort_avg_speed")
)
.with_columns(
(pl.col("SOG") > (pl.col("cohort_avg_speed") * 10)).alias("is_speed_anomaly")
)
.filter(pl.col("is_speed_anomaly"))
)
The defaults are intentionally simple: RayEngine uses all visible GPUs and starts one Ray worker per device. We can tune the engine later, but first let's run something real enough to stress the system.
And this immediately fails with an OOM -- a not uncommon user experience ;)
(RankActor pid=699246) [2026-06-16 17:07:10,190 E 699246 701128] logging.cc:118: Unhandled exception: N3rmm13out_of_memoryE. what(): std::bad_alloc: out_of_memory: CUDA error (failed to allocate 368974272 bytes) at
: /tmp/conda-bld-output/bld/rattler-build_librmm/work/cpp/src/mr/cuda_async_view_memory_resource.cpp:43: cudaErrorMemoryAllocation out of memory /localhome/local-bzaitlen/rapids-2608-nightly/lib/python3.14/site-pac
kages/ray/_raylet.so(+0x15d4368) [0x7bc9539d4368] ray::operator<<()
Often though, we need to tune the system and may want to configure various parameters in cuDF-Polars, RapidsMPF, or even Ray. Still, the defaults should be a good starting point, and the defaults for RayEngine are to use all devices on the system. It's recommended to use the StreamingOptions dataclass. We can set everything related to the how the query is executed: spill_device_limit, fallback_mode, target_partition_size , etc and we can also configure the Ray Actors as well.
The default spill_device_limit is 80%. Let's lower it to 70%, and while we are at it, having easy access to the dashboard remotely would be quite helpful:
opts = StreamingOptions(
spill_device_limit="70%",
)
ray_init_options = {
"include_dashboard": True,
"dashboard_host": "0.0.0.0",
"dashboard_port": 8265,
}
with RayEngine.from_options(opts, ray_init_options=ray_init_options) as engine:
query.sink_parquet(OUTPUT_DIR, engine=engine)
This time the query runs cleanly. In the GIF below, all four T4s turn on and stay busy for most of the query. That is the main thing I wanted to see. Our cycle has been: 1. Take a Polars query and naively run it on multiple GPUs. 1. Hit an OOM. 1. Tune the engine and re-run. 1. Success!

I'm not terribly confident in the domain analysis. On the surface it seems plausible, but it probably deserves more scrutiny from someone who knows AIS data better than I do. As a systems exercise, though, this is exactly the kind of workload I hoped for: large enough to require multi-GPU execution, memory intensive enough to require spilling, and communication-heavy enough to make the execution engine do real distributed work.
In [10]: (
...: pl.scan_parquet('/localhome/local-bzaitlen/ais-cudf-polars/output/result/*.parquet')
...: .group_by('VesselType')
...: .agg(pl.len().alias('anomaly_count'))
...: .sort('anomaly_count', descending=True)
...: .limit(5)
...: .collect()
...: .with_columns(
...: pl.col('VesselType').map_elements(lambda x: VESSEL_TYPES.get(x, f"Unknown ({x})"), retur
⋮ n_dtype=pl.String).alias('VesselTypeName')
...: )
...: )
Out[10]:
shape: (5, 3)
┌────────────┬───────────────┬───────────────────┐
│ VesselType ┆ anomaly_count ┆ VesselTypeName │
│ --- ┆ --- ┆ --- │
│ i64 ┆ u32 ┆ str │
╞════════════╪═══════════════╪═══════════════════╡
│ 52 ┆ 547390 ┆ Tug │
│ 30 ┆ 262985 ┆ Fishing │
│ 70 ┆ 252750 ┆ Cargo │
│ 60 ┆ 216759 ┆ Passenger │
│ 51 ┆ 193884 ┆ Search and rescue │
└────────────┴───────────────┴───────────────────┘
Turns out it's mostly the Tugs which operate at 10x the average speed. I suppose that makes some sense; Little Toot liked the figure-eights in the harbor but could only go so fast when pulling in the big ocean liners.
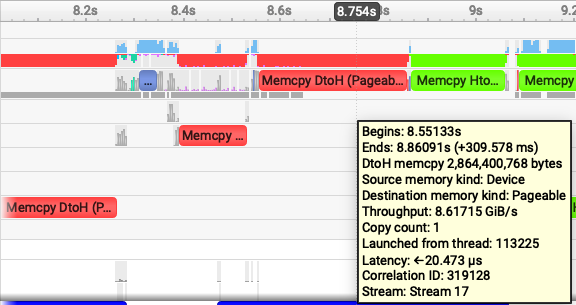
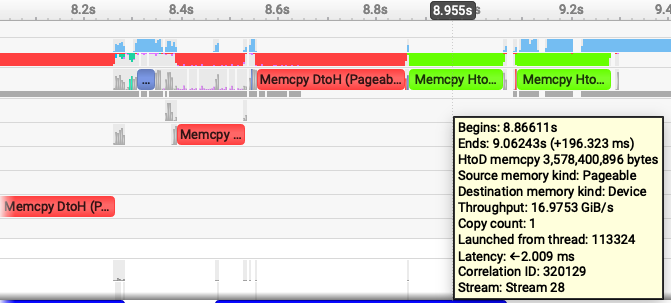
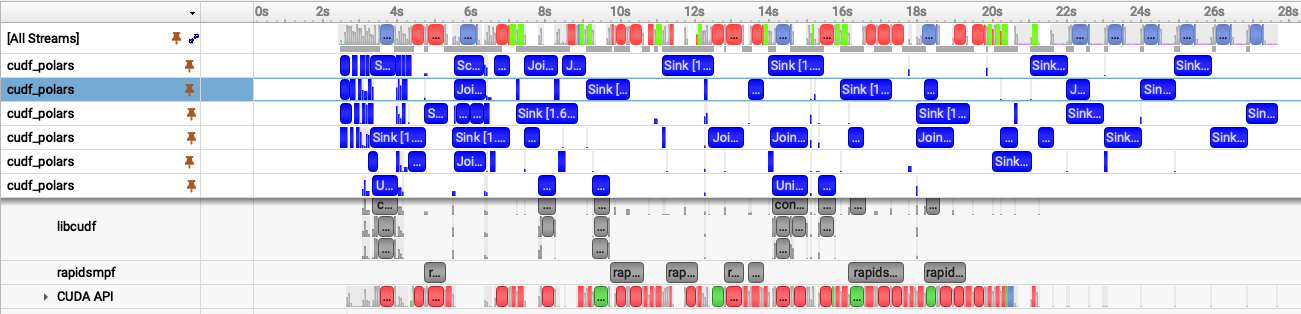 Fig 1. Nsight Systems timeline showing the pageable-memory cudf-polars join workflow.
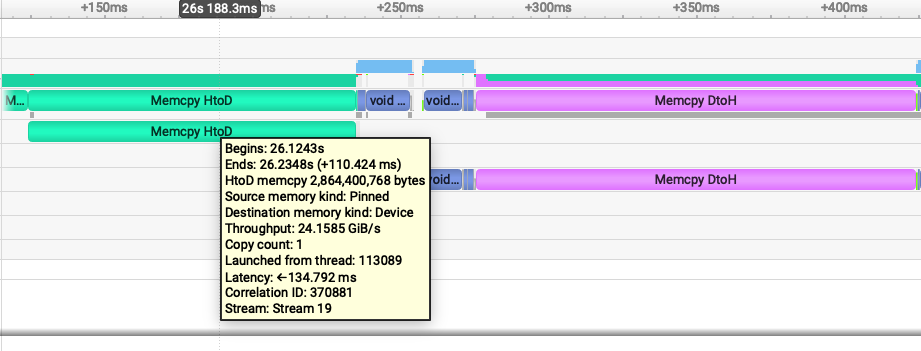
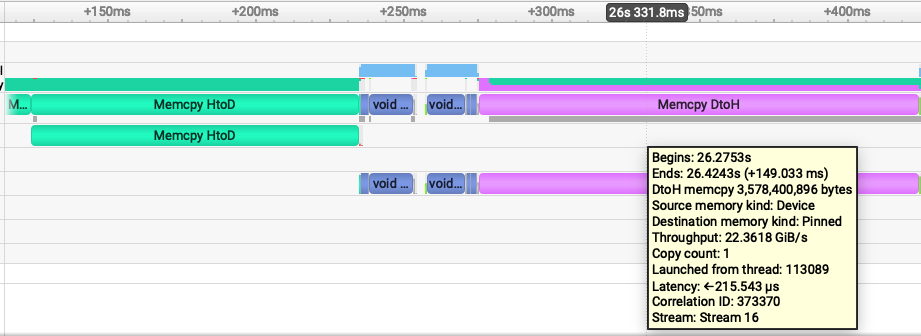
Fig 1. Nsight Systems timeline showing the pageable-memory cudf-polars join workflow.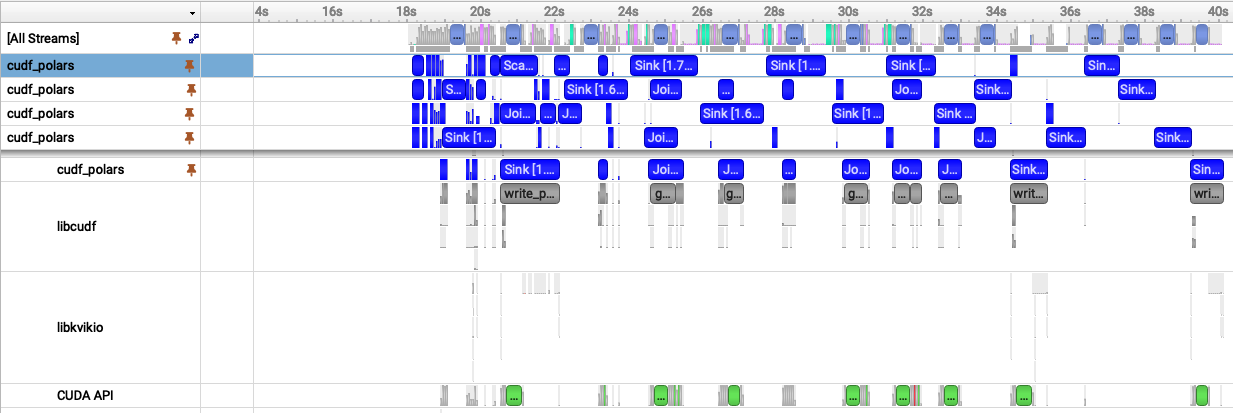 Fig 2. Nsight Systems timeline showing the pinned-memory cudf-polars join workflow.
Fig 2. Nsight Systems timeline showing the pinned-memory cudf-polars join workflow.